|
EasyOCR is a Scorpion wrapper for the Euresys eVision EasyOCR
ActiveX control.
The control is licensed separately, see http://www.euresys.com/
and requires a Euresys usb-dongle to run.
When installing Scorpion it is required to select and install the eVision
module in the Scorpion Setup. The tool was originally based on eVision
Version 6.6. A compatible and complete set of files are installed when
installing Scorpion.
EasyOCR is a library dedicated to automatically locate and decode
characters. Prior to its use, the OCR engine must be presented with a sample
set of characters to recognize. Character location and segmentation is
performed automatically; the user must simply identify each sample
character. The library has the following features
- Completely integrated training
- Very fast
- Character scaling support
- Automatic compensation of illumination changes
- Direct contrast (black on white) and inverse contrast (white on
black) support
The tool will detect and report (presently) all matched characters in the
ROI as a single long string, and in addition details for all matched and
unmatched characters in the image (including position and scores).
Background information
Setup
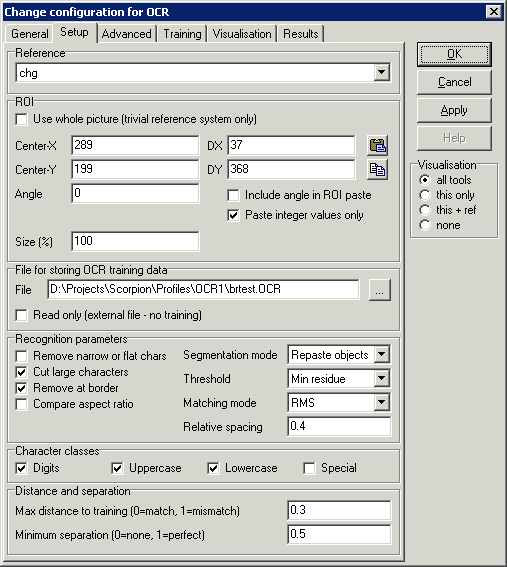
Reference - Reference system selection
ROI (Region of interest)
- Use whole picture - only possible if the reference is trivial,
i.e., with no calibrator, perspective, rotation or scaling.
Position/size is ignored if this is checked.
- Center-X - x
- Center-Y - y
- dX - height
- dY - width
- Angle - rotation of image
- Include angle in ROI paste - if unchecked, pasted rectangles
will be at zero angle (faster processing)
- Paste integer values only - if checked, pasted rectangles are
forced at pixel centers (faster processing)
- Size - resampling of the incoming image to shrink/grow.
The ROI can be managed by the buttons

- Paste - paste the ROI from the image to the scorpion clipboard
- Copy - copy the ROI to the image from the scorpion clipboard
Point & Click Clipboard Support
 The rectangular
ROI
is defined by four points. The rectangular
ROI
is defined by four points.

One point will change the center point.
More on Image Operations.
File for storing OCR training data
The OCR training data is always stored in an external (*.OCR) file. This
file is compatible with any program using the Euresys OCR library.
- Read only - training is disabled -- name an external OCR file,
e.g., one created with the Euresys EasyAccess program.
Recognition parameters
These parameters are kept separate from the training parameters. For a
detailed description, refer to the Euresys documentation. Note that the
settings should always be kept identical during training and recognition, where
applicable; this is automatically taken care of when using the training
system, so you will normally never need to change any settings here with the
possible exception of "Compare aspect ratio".
- Remove narrow or flat chars - by default, narrow AND flat
characters are removed (ignored). Check this to ignore characters that
are either narrow or flat.
- Cut large characters - if checked, an attempt is made to cut
too large characters into smaller (may help with e.g. ink bloating). if
unchecked, large characters are ignored.
- Remove at border - if checked, characters at ROI edges are
ignored.
- Compare aspect ratio - if checked, stretched or flattened
characters get lower score
- Segmentation mode - "repaste objects" means that e.g.
the dot over "i" is connected to the stem prior to
recognition.
- Threshold - Euresys recommends using "Min residue".
- Matching mode - Euresys recommends using "RMS".
- Relative spacing - Used only when Cut large characters
is checked; a number larger than 0 forces a space between the split
parts.
Character classes
When training, characters can be classified as Digits, Uppercase,
Lowercase or Special characters. Only those selected are included in the
matching process.
Distance and separation
Filters out characters found that have a low match:
- Max distance to training - normalised distance to training
data. Use higher value (0<=v<=1) to accept poorer match
- Minimum separation - match distance ratio between best two
matches. Use lower value (0<=v<=1) to accept similar characters
Advanced
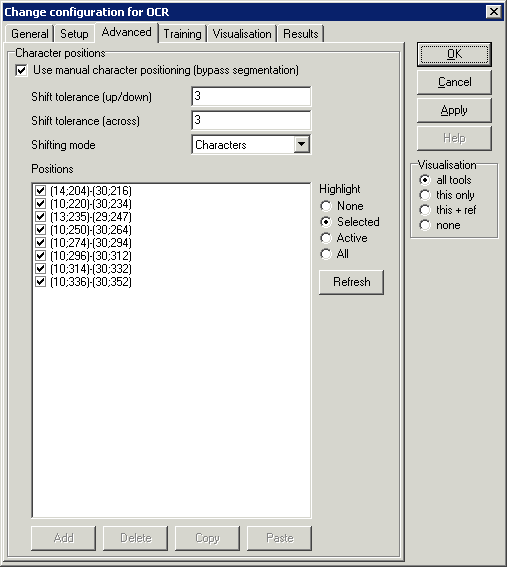
By default, the OCR library will automatically segment potential
characters in the image. This can be bypassed here.
Character positions
- Use manual character positioning (bypass segmentation) - check
this to enable manual positioning
- Shift tolerance (up/down) - maximum movement of the manually
set position for best match
- Shift tolerance (up/down) - maximum movement of the manually
set position for best match
- Shifting mode -
- Characters - each character is moved separately
- Text - all characters are moved as a whole
- Positions - list of manually added positions (shown as pixel
coordinates within the ROI)
- Add - add new position from rectangle clicked in the main
image
- Delete - delete selected position
- Copy - copy selected position back to the main image
- Paste - modify selected position from rectangle clicked in
the main image
- Highlight - positions can be temporarily highlighed in the main
image
- None - highlight nothing
- Selected - highlight only the selected position
- Active - highlight the checked (active) positions
- All - highlight all positions
- Refresh - highlights will disappear under a number of
circumstances - click refresh to update
- List right-click menu
- Add - same as button
- Delete - same as button
- Copy - same as button
- Paste - same as button
- Delete all - delete all positions in the list
Training
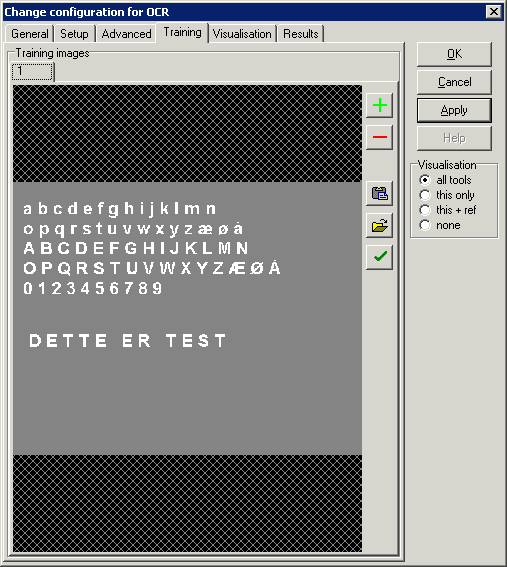
You can include any number of sample images for training the
characters. These can be read from file or copied from e.g. the Scorpion main
image.
-
 Add room for a new image Add room for a new image
-
 Delete selected image and
all its training data Delete selected image and
all its training data
-
 Paste image from the
clipboard Paste image from the
clipboard
-
 Load image from file Load image from file
-
 Perform interactive
training on the selected image (see OCR training below) Perform interactive
training on the selected image (see OCR training below)
Image right-click menu
OCR training
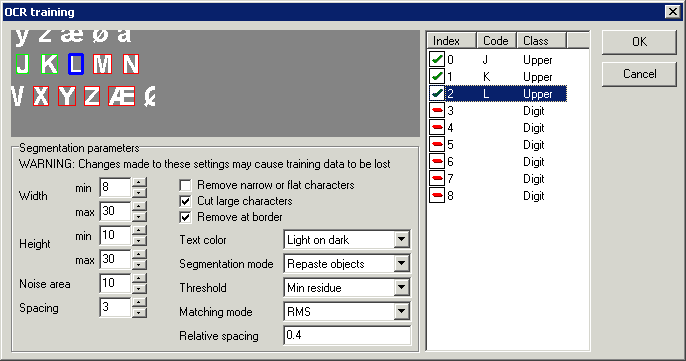
The image is automatically segmented based on these parameters:
- Width min/max - max single character size
- Height min/max - min single character size
- Noise area - smallest area to be considered
- Spacing - minimum space between adjacent characters
- Remove narrow or flat characters - by default, narrow AND flat
characters are removed (ignored). Check this to ignore characters that
are either narrow or flat.
- Cut large characters - if checked, an attempt is made to cut
too large characters into smaller (may help with e.g. ink bloating). if
unchecked, large characters are ignored.
- Remove at border - if checked, characters at ROI edges are
ignored.
- Text color - "Light on dark" or "Dark on
light" are meant to be used with the threshold and matching mode
settings (below)
- Segmentation mode - "repaste objects" means that e.g.
the dot over "i" is connected to the stem prior to
recognition.
- Threshold - Euresys recommends using "Min residue".
- Matching mode - Euresys recommends using "RMS".
- Relative spacing - Used only when Cut large characters
is checked; a number larger than 0 forces a space between the split
parts.
After the segmentation is done, any previously assigned character
codes/classes are applied. If the segmentation parameters are changed, the
assigned codes are kept as far as possible.
| WARNING: when the segmentation parameters are
changed, this applies to all training images. You should
revisit and check all images for consistency after making any
changes. |
The found characters are displayed in red. Clicking a character
highlights the corresponding item in the list on the right. Doubleclicking a
list item (or pressing RETURN when the item has focus) brings up the learning dialog (below). The item selected in the
list is also highlighted in blue in the image. When a code and class has
been assigned to a character, they are shown in green in the image.
List right-click menu items
- Edit - same as double-click
- Activate - shortcut to (re)activate a previously deselected
item
- Deactivate - remove character from recognition process
In the "Selected pattern" dialog you teach the OCR which
character it has found.
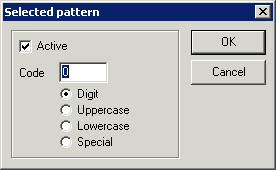
- Active - the character is used in the recognition only if
checked
- Code - Single-character code
- Digit/Uppercase/Lowercase/Special - Pattern class, used for
recognition selection/classification
Visualisation
|
BadSegment |
Found but not accepted character rectangle
|
|
Character |
Found character code
|
|
ReadString |
All characters found, in sequence
|
|
ROI |
Search area
|
|
Segment |
Found character rectangle
|
Results
|
Whole picture |
1: whole picture was searched; 0: specified ROI was used |
|
Trivial refsys |
1: reference system is trivial - whole picture may be used; 0: not
trivial - whole picture not available |
|
Read string |
All character codes, in sequence |
|
Number of accepted |
Number of recognised characters |
|
Number of not accepted |
Number of refused characters |
|
Characters |
All characters, as Python dictionary tuple |
|
Accepted |
All accepted characters, as Python dictionary tuple |
|
Not accepted |
All refused characters, as Python dictionary tuple |
The Python dictionary strings contain this information, as a tuple of
dictionaries:
- OK - 0 or 1
- Code - character code as a single character
- Class - "Digit", "Upper", "Lower" or
"Special"
- Pos - Object coordinates of top left character corner
- Dist - distance to training data
- Sep - ratio of separation to next possible match
Example of Characters string for two found characters "B" and
"d":
({'Code': 'B', 'Dist': 0.0, 'Sep': 1.0, 'Pos': (224.0, 243.0), 'OK': 1, 'Class': 'Upper'},{'Code':
'd', 'Dist': 0.0, 'Sep': 1.0, 'Pos': (224.0, 262.0), 'OK': 1, 'Class':
'Lower'})
ExecuteCmd support (see also executeCmd)
|
Command
|
Parameters
|
Return values
|
Comments
|
| Set |
Object=ROI;Value=<point/polygon> |
ok,res |
Sets
the tool's ROI. See Copy/paste
ROIs for details. |
| Get |
Object=ROI |
ok,<polygon> |
Current
ROI (angled rectangle). |
|
